Développement logiciel :
qu'est-ce qui a changé ?
Bastien Vigneron
379 km, environ 1 heure « porte-à-porte » (d'embarquement) pour 41 minutes de vol, soit grossièrement le même temps qu'en TGV pour la même distance. Il s'agit de la ligne aérienne la plus courte opérée en A380, inaugurée en été 2019 par Emirates entre Dubaï et Doha.
Durant ce vol, environ 14 tonnes de kérosène sont brûlées dans l'atmosphère...
Vous trouvez cela absurde ? Pourtant des centaines de milliers d'entreprises se comportent de la même façon avec leur IT (information technology), la plupart du temps sans même s'en rendre compte.
Loi de Moore et euphorie
Revenons quelques années en arrière, une trentaine : nous sommes au début des années 90, la « micro » est en pleine explosion dans les entreprises.
Le « Cloud » n'existe pas encore et l'informatisation massive, le début de la « révolution numérique », passe alors par l'équipement.
Toutes les grandes entreprises veulent leur Datacenter, ou à minima leur salle serveur.
Des constructeurs comme Sun Microsystem, HP, Silicon Graphics, IBM, en France Bull se partagent le marché des serveurs Unix avec leurs matériels et architectures propriétaires tendit que Microsoft convainc de plus en plus de petites et moyennes entreprises de rejoindre leur écosystème sur des serveurs Intel, bien meilleur marché.
Linux n'existe pas encore, pas plus que Google.
Le balancier de l'informatique d'entreprise est alors clairement du côté du CAPEX : de l'investissement et de l'amortissement.
On achète des gros serveurs que l'on amortit sur 3,5 voir 10 ans et ce, qu'ils soient utilisés à 5,50 ou 100 % de leurs capacités.
L'industrie logicielle entre à peine dans sa phase de maturité, le SaaS et le PaaS n'existent bien évidemment pas encore, et la stratégie dominante oscille entre acquisition auprès d'éditeurs (pour une installation « on prémisse ») et développements internes.
La loi de Moore, qui prévoit un doublement du nombre de transistors des CPUs à prix constant tous les 24 mois, bat son plein, Intel sort son Pentium en 1993 et ne la fera pas mentir pendant près de 10 ans.
Dans ce contexte d'hyper-inflation des performances matérielle, la gestion de la performance logicielle est moins un sujet que la productivité de développeurs, qui déjà, sont une ressource rare et coûteuse.
Les travaux de recherche sur la théorie des langages et un certain nombre d'initiatives individuelles donnent naissance à de nouveaux langages, visant précisément la productivité des développeurs bien avant la performance pure (il suffit de toute façon d'attendre deux ans pour que les programmes tournent deux fois plus vite sans rien faire à part renouveler le matériel).
Perl voit le jour en 1987, Python en 1991, Ruby en 1995, Java en 1996 plus un certain nombre d'autres « environnements de développement » tel que WinDev (et ses publicités aguicheuses) en 1993 ou encore Delphi en 1995.
La course à l'informatisation s'accélère, il faut développer vite, quitte à le faire mal.
La course à la productivité
En 1994, le Standish Group publie son premier « Standish Chaos Report » [1] qui analyse les taux de succès et la nature des échecs des projets informatiques d'entreprise.
Le constat est sans appel, prêt de 90 % des projets sont un échec : soit le budget initialement prévu a largement été dépassé (prêt de la moitié d'entre-deux l'ont doublé), soit le logiciel à du finalement être sortie en sacrifiant une partie des fonctionnalités, soit le projet à carrément été annulé et enterré sans parler bien entendu des retards de livraisons à répétition.
Aucune autre industrie n'accepterait un tel désastre qualitatif.
Pour tenter de corriger le tir, on invente de nouvelles méthodes de gestion de projet : le cycle en V, Merise, AGL, on standardise de plus en plus le matériel (Intel et Microsoft en profitent largement) et le logiciel (modèle ISO, ASN.1, XML, X500...).
Malgré ce tableau peu reluisant, les performances matérielles continuent leur progression, quasi-linéaire sans l'ombre d'un quelconque ralentissement à l'horizon.
Les ventes d'équipement se portent bien, puisqu'il faut les machines de demain pour faire tourner les programmes développés à la hâte aujourd'hui.
Les concepteurs de langages sont par conséquent encouragés à pousser encore plus loin le levier de la productivité, au détriment de la performance, et peut-être un peu aussi de la qualité.
Le modèle objet connais un succès croissant, les langages interprétés séduisent de plus en plus, PHP, qui fait sa première apparition en 94, démocratise le développement Web alors naissant.
Toujours plus d'abstractions, toujours plus d'indirection, toujours plus de couches, quelque qu'en soit le « coût », on sait qu'il sera absorbé par la prochaine génération de CPU.
Mais ça, c'était avant. Avant le drame.
Un vent de panique
En 2004 se produit un évènement que les concepteurs / fondeurs de CPU redoutaient depuis longtemps.
Si le nombre de transistors continue de doubler tous les 24 mois comme le prévoit la loi de Moore, ce doublement n'est plus directement traduit en augmentation de la puissance brute disponible, ou devrais-je dire, facilement disponible.
En effet, la croissance ininterrompue de la puissance des CPUs s'exprimait jusqu'alors par la capacité des CPUs à exécuter un flux d'opérations de façon toujours plus rapide.
Lorsque l'on parle d'augmentation « gratuite » des performances, cela n'implique pas que les nouvelles machines étaient offertes aux clients, mais que ces derniers n'avaient rien de particulier à faire dans leurs programmes pour profiter de l'amélioration (même pas une recompilation).
En 2004 les fondeurs ont atteint une limite thermique résultant d'une part de la croissance du nombre de transistors et d'autre part de l'augmentation de la fréquence de fonctionnement des processeurs.
Les fréquences se sont alors mises à stagner depuis lors.
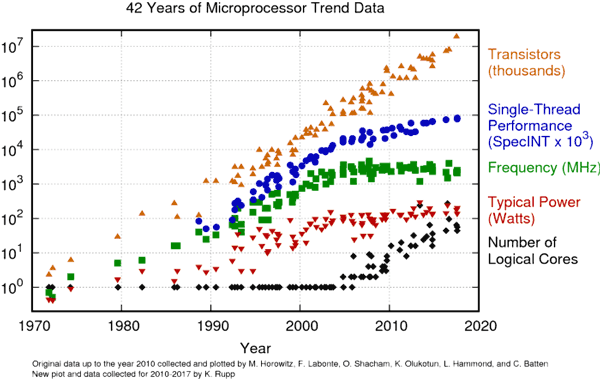
L'amélioration de la finesse de gravure des CPUs a malgré tout permis de satisfaire M. Moore. On a réussi à mettre toujours plus de transistors sur une même surface de silicium et dans une même enveloppe thermique, mais il fallait les exploiter différemment.
Sont alors apparus (ou plutôt se sont alors généralisé) les processeurs dits « multicoeurs ».
Avant 2004, l'objectif des fondeurs était de traiter les instructions toujours plus vite, passé cette année charnière, la bataille s'est déplacée sur le terrain de la parallélisation : leur capacité à traiter de plus en plus d'instruction de façon simultanée.
Le graphique ci-dessus montre clairement la concordance de la stagnation de la fréquence avec le début du décollage du nombre de coeurs logique. Le nombre de transistors, lui, continue d'augmenter tranquillement (un CPU bicoeurs implique environs le double de transistors qu'un CPU monocoeur – même si ce n'est pas aussi simple en réalité).
Pour la première fois depuis plus de trois décennies, mettre à jour son infrastructure ne permettait plus d'augmenter « gratuitement » les performances de programmes.... qui avaient pour l'immense majorité été conçus pour fonctionner de façon linéaire (non parallélisé) et donc incapable d'exploiter les coeurs additionnels et le surplus de transistors.
La gueule de bois
Fini l'augmentation gratuite des performances, l'absorption systématique des nouvelles abstractions, d'indirection, de surcouches.
Cette fois, le développeur à trois choix s'il veut améliorer les performances de ses produits :
Revenir à des langages de plus bas niveau et optimiser ses programmes : mais la productivité risque d'en prendre un sacré coup. S'adonner à la programmation parallèle : mais c'est beaucoup plus difficile, source d'erreurs multiples difficilement prédictives et reproductibles (race conditions, dead-lock, gestion hasardeuse des mutex...), elle nécessite un niveau de compétence bien plus élevé et trop rare sur le marché pour être généralisée. Découper les gros programmes en plusieurs modules plus petits (mais toujours monothread) qui pourront s'exécuter en parallèle et donc utiliser un tant soit peu la puissance disponible.
C'est essentiellement la troisième solution, la moins coûteuse et la moins risquée, qui sera privilégiée.
Ont vois alors apparaître de nouveaux paradigmes : les architectures multi-tiers, puis orientés services suivis enfin par les architectures microservices encore en vigueur aujourd'hui.
Ainsi, un gros programme monolithique conçus dans les années 90-2000 peut être découpé en petits modules (disons une vingtaine) qui collaboreront ensemble, chacun consommant l'équivalant d'un coeur de CPU, pour délivrer le même service.
Évidemment déployer, surveiller et exploiter 20 programmes coûte plus cher qu'un seul, il a donc fallu trouver un moyen d'automatiser ces tâches pour éviter le désastre économique : dites bonjour à Docker et Kubernetes.
Tous n'est pas perdus pour tout le monde...
Nous avons d'un côté de nouvelles architectures CPUs que les entreprises peinent à utiliser de façon optimale et de l'autre des systèmes de déploiement et d'exploitation automatisés de plus en plus performants.
Ne serait-ce pas une bonne idée alors de mutualiser une infrastructure multicoeur entre plusieurs entreprises ?
Ainsi naquit le Cloud.
Les années 2010 voient fleurir de nouveaux types d'offres, une nouvelle révolution qui n'est pas tant technologique qu'économique.
Au lieu d'investir dans du matériel qu'elle amortira sur plusieurs années malgré une utilisation plus que partielle, l'entreprise peut désormais louer son utilisation pour une fraction de son prix puisque plusieurs entreprises se partageront (en principe de façon inconsciente) la même infrastructure matérielle.
Du CAPEX nous basculons vers l'OPEX [2] : et ça change tout pour le développeur.
Les coûts de l'entreprise vont désormais être directement proportionnels à la performance de ses programmes (ce que beaucoup d'entreprises n'ont pas encore intégré).
Plus ces derniers sont performants, moins ils consomment de ressources (temps CPU, RAM, stockage, réseau), moins élevé sera la facture du « Cloud provider », cette dernière étant basée sur le principe du « Pay-as-you-use ».
Nous sommes en 2021, et force et de constater :
Qu'une grande partie des entreprises n'en a pas encore complètement pris conscience. Que celles qui en ont pris conscience découvrent avec effrois l'ampleur des dégâts provoqués par 25 ans de priorité à la productivité.
Dette technique
Les modèles d'infrastructures ont évolué bien plus rapidement que les pratiques de développement.
Les offres d'emplois du marché des développeurs sont relativement parlantes : les langages qui caracolent en tête du classement [3] des plus demandés sont ceux des années 90, conçues en privilégiant la productivité du développeur en sacrifiant la performance (ou l'utilisation efficace des ressources).
Par exemple :
JavaScript [4] : un langage interprété dont les performances catastrophiques n'ont d'égales que son niveau de fiabilité et de sécurité Python [5] : encore un langage interprété, adulé par les Datascientist et autres amateurs de RAD (Rapid Application Development). Il a au moins le mérite par rapport à JavaScript d'introduire la notion de programmation typée (bien qu'elle reste dynamique) diminuant un peu le spectre d'erreurs potentielles. Java [6] : lancé en 1996, une époque ou la diversité des architectures CPU était encore importante, avec une promesse séduisante : « Write once, run anywhere ». Il introduit un nouveau concept, c'est un langage compilé, mais pour un CPU qui n'existe pas. Le « bytecode » produit par cette dernière est en effet exécuté sur une machine virtuelle (la JVM) qui le convertira à la volée en code exécutable par le CPU physique sous-jacent.
Arrêtons-nous sur ce dernier qui représente encore la majorité du code applicatif de gestion en entreprise.
La promesse initiale était séduisante, dans les années 2000, décennie qui a vu sa popularité exploser, le parc serveur des entreprises était encore très varié :
des serveurs Unix (ou chaque constructeur avait son OS et son architecture CPU propriétaire), des serveurs « Wintel » (Windows + Intel), et encore pas mal de mainframes pour les plus grandes.
Le développement applicatif était par conséquent découpé en autant de silos que de cibles matérielles, avec pour chacun d'entre eux des outils dédiés (IDE, compilateurs, outil de build, débugeur, librairies, framework...) et des compétences humaines dédiées.
C'était un véritable frein à la mutualisation des développements et à la rationalisation des équipes.
La promesse d'une technologie qui permet d'écrire un code une seule fois quelle que soit la plate-forme cible relevait alors du miracle : LA solution pour beaucoup d'entreprises.
Java a aussi popularisé un concept jusque là relativement confidentiel : la programmation-objet.
La capacité à réutiliser plus facilement du code, écrit par soi même ou par d'autres : encore des gains de productivités en perspective.
Il a connu un succès fulgurant, il passe de la 26e place du classement TIOBE [7] en 1996 à la 3e en 2001 et obtient le podium des langages les plus populaires en 2005 (place qu'il ne perdra qu'en 2012).
Son adoption est incontestable et il commence à être enseigné dans les écoles d'ingénieur.
Mais comme en informatique, la magie n'existe pas, ses deux principales qualités (universalité et productivité) se payent une fois de plus sur le terrain de la consommation des ressources.
Java souffre de deux gros problèmes :
Une consommation mémoire gargantuesque : 20 à 100 fois plus élevée qu'un programme équivalent écrit en C par exemple. Un temps de démarrage très lent, car la JVM doit analyser de bytecode et sont utilisation réelle lors de l'exécution pour en optimiser la transcription en code natif.
Boulimie et ressources finies
Java est gourmand, très très gourmand, particulièrement en ce qui concernant la mémoire vive des machines sur lesquelles il s'exécute.
Cette boulimie s'explique par trois propriétés du langage :
Son mode de fonctionnement : compilation « just in time » : au moment de l'exécution, qui recourt massivement à l'introspection, gourmande en ressource. Son mode de gestion de l'allocation mémoire : tous les objets Java sont alloués dans la heap, la moins performante, et en Java, tout est objet. Son modèle objet : s'il facilite la réutilisation du code, il favorise aussi le chargement peu maîtrisé de code inutile.
Il existe deux types de ressources sur un ordinateur : les ressources finies et les ressources infinies.
La mémoire et le stockage sont des ressources finis : la machine en dispose d'une quantité fixe (ex : 64Go de RAM et 2To de disque), elle n'augmente pas avec le temps (sauf à en rajouter physiquement). Le CPU est une ressource infinie : Le nombre de cycles, et donc, d'opérations qu'il réalise, augmente avec le temps qui lui est a priori infinie (bien que tous les physiciens ne soient pas encore certains de cette hypothèse). Sa vitesse est constante dans le temps (il n'accélérerait pas en vieillissant, mais ne ralentit pas non plus), mais plus le temps passe plus la somme des opérations réalisées augmente.
Les Clouds provider ont bien évidemment construit leur modèle de prix en faisant essentiellement payer l'utilisation des ressources finies, la RAM et/ou le stockage.
Un logiciel écrit en Java, consommant a priori beaucoup plus de RAM que son équivalent écrit dans un autre langage sera en conséquence bien plus coûteux à l'utilisation.
L'incompatibilité avec le modèle microservice
Java a été conçu et popularisé à une époque ou le monolithe était rois, le gros logiciel s'exécutant sur un gros serveur qui appartient à l'entreprise et qu'elle est la seule à utiliser.
Son temps de démarrage n'avait aucune importance dans la mesure ou il était démarré une fois pour ensuite tourner jour et nuit sans s'arrêter, qu'il y ait des utilisateurs pour le consommer ou pas.
Dans la mesure ou l'entreprise amortissait financièrement le serveur qu'il soit utilisé ou pas, le fait qu'il soit chargé à 5 ou 100 % de ces capacités n'était pas un sujet. Le fait que ses ressources disponibles soient gaspillées n'était pas important.
Beaucoup de DSI dans les années 90-2000 mesurait même leurs succès et leur importance au nombre de machines alignées dans leurs salles serveur. Les préoccupations écologistes n'étaient malheureusement pas encore d'actualité.
L'avènement des architectures microservices et des orchestrateurs pour les raisons explicitées plus haut a changé la donne.
Puisque les microservices continuent à être majoritairement incapables d'exploiter les capacités multithread / multicoeurs des CPUs moderne, ont a eu l'idée d'augmenter la capacité de traitement du système en multipliant le nombre d'instances de chaque microservice auxquels un load-balancer frontal distribue généralement le travail.
Les orchestrateurs modernes pouvant aisément détecter la limite de capacité de traitement d'une instance, ils déclenchent alors de lancement d'une nouvelle instance du service et équilibrent ensuite le trafic entre elles.
Lorsque ce dernier diminue, l'orchestrateur va « décomisioner » les instances inutiles afin de faire baisser la réservation / consommation des ressources et donc la facture du client (Pay-as-you-use), on parle d'élasticité.
Mais cette élasticité suppose que :
Le démarrage d'une nouvelle instance est suffisamment rapide pour ne pas pénaliser les utilisateurs qui l'ont déclenché (une ou deux secondes maximum) Que ce démarrage n'implique pas un pic de consommation élevé de ressources
Or c'est exactement l'inverse qui se produit avec un programme utilisant la JVM.
Ce dernier peut mettre 30 secondes (voir beaucoup plus) à démarrer pendant lesquels il engloutira une quantité phénoménale de cycles CPUs et de Go de RAM.
Dans le monde de l'infra ont dit que la JVM « chauffe », comme un vieux diesel en quelques sortes.
Il est donc évident que les technologies basées sur la JVM (Java, Scala, Kotlin, Groovy, JRuby...) ne sont pas les candidats idéaux pour le nouveau paradigme du Cloud... malgré leurs hyperprésences dans le parc applicatif des entreprises.
Réécrire ses applications avec des technologies privilégiant enfin la performance et le traitement multithread prendra du temps, des années, des décennies probablement, on appelle cela (entre autres) : la dette technique.
Un souffle nouveau
Récrire (ou écrire) les logiciels d'entreprise avec des technologies modernes, mieux adaptées au matériel et paradigmes de déploiement modernes suppose que ces technologies existent.
C'est le cas. Depuis une dizaine d'années, nous voyons fleurir de nouveaux langages, qui essaient de concilier, dans la mesure du possible, productivité et performance.
Go [8] et Rust [9] en sont les deux représentants les plus significatifs.
Ils ont tous les deux étés conçu en tenant compte du nouveau paysage informatique : des architectures massivement multicoeurs et un paradigme de déploiement reposant sur l'élasticité.
Ils sont tous les deux fortement typés, et compilés pour de vrai CPUs visant ainsi un niveau de performance et d'efficacité inatteignables pour un langage interprété ou semi-compilé comme Java.
Ils excellent tous les deux dans la gestion de la programmation concurrente, de la performance de la sécurité et de la consommation raisonnée, mais efficace des ressources matérielles.
Productivité et performance étant plutôt antinomiques, ils abordent en revanche les limites de l'exercice avec une approche différente :
Lorsque les limites sont atteintes, Go [10] privilégie la simplicité et la productivité. Lorsque les limites sont atteintes, Rust [11] privilégie la performance et la sécurité.
Leurs popularités et leurs adoptions commencent sérieusement à décoller, mais le chemin sera encore long avant qu'ils prennent la place de Java et Python en entreprise.
À titre personnel, je me réjouis de leurs disponibilités et j'appelle de mes voeux tous les développeurs à s'y intéresser : pour la planète, et tous les dirigeants et décideurs : pour leurs comptes d'exploitation.
La promesse enfin délivrée
Je n'étalerais pas ici de chiffres comparatifs de performances et de consommation de telle ou telle implémentation d'un programme dans les différents langages, le web en regorge [12].
Je confirmerai simplement que mon expérience personnelle atteste de différences manifestes et suffisamment importantes pour justifier dans bien des cas le financement de la réécriture de nombre de programmes d'entreprise avec ces langages modernes.
Le gain financier en coût de « Run » (c.-à-d. la facture du cloud provider) absorbant souvent rapidement l'investissement nécessaire à la réécriture du logiciel.
Il n'est par ailleurs pas exclut qu'a cette occasion, ce dernier se débarrasse d'un certain nombre de bugs historiques en profitant des nouveaux mécanismes de sécurité et de contrôle qualité (ex : mécanismes de tests unitaires intégrés, gestion automatique ou sécurisée de la mémoire, modèles simplifiés, mais efficaces de programmation concurrente...) de ces langages.
La promesse du Cloud, a savoir une baisse des coûts d'infrastructure, et de l'IT en général, c'est avéré être un mirage pour beaucoup d'entreprises qui, tout comptes faits, peinent à justifier leur bascule sur un angle purement financier.
On met alors souvent en avant d'autres avantages supposés tel que l'agilité, la maîtrise du risque et celui que je préfère d'entre tous : le recentrage sur le coeur de métier de l'entreprise ;-)
La réalité n'est pourtant pas si éloignée de la promesse :
En mutualisant les infrastructures dans des Datacenter géants ultra-optimisés on fait effectivement baisser la consommation moyenne par entreprise. On leur permet effectivement de ne payer les ressources que lorsqu'elles sont utilisées. Elles ont effectivement l'accès à une souplesse et une élasticité des capacités de traitements inimaginables auparavant.
Mais pour atteindre cette réalité, il est impératif que les équipes de développement (ou les éditeurs) de ces dernières déterrent une compétence souvent oubliée depuis des décennies dans l'informatique de gestion : la recherche de la performance et de l'efficacité logicielle.
Conclusion
Il semblerait que notre industrie évolue par cycles d'environs deux décennies.
Les mainframes ont régné sur le monde entre les années 70 et 90, la micro a connu son apogée au bout d'une quinzaine d'années puis le paradigme du Cloud est apparue en 2005, il aura mis 5 ans à réellement percer pour devenir la norme par défaut dès 2010.
On peut supposer qu'il la restera au moins jusqu'en 2030.
L'investissement dans la performance, l'élasticité et la qualité logicielle (parfois au prix d'une petite baisse de productivité des développeurs) n'est donc pas un pari irraisonné, d'autant que rien ne nous permet de penser que nous retrouverons l'augmentation « gratuite » des performances des années 90–2004 dans un avenir proche.
Je suis pour ma part intimement convaincue qu'il en vaut la peine, financièrement, écologiquement et intellectuellement.
Bastien Vigneron
Paru le 2 juin 2021 sur le site de Bastien Vigneron :
https://bastienvigneron.medium.com/développement-logiciel-quest-ce-qui-a-changé-b8f0518606da
NOTES
[1] https://www.projectsmart.co.uk/white-papers/chaos-report.pdf
[2] https://fr.wikipedia.org/wiki/CAPEX_-_OPEX
[3] https://bootcamp.berkeley.edu/blog/most-in-demand-programming-languages/
[4] https://fr.wikipedia.org/wiki/JavaScript
[5] https://fr.wikipedia.org/wiki/Python_( langage)
[6] https://fr.wikipedia.org/wiki/Java_( technique)
[7] https://www.tiobe.com/tiobe-index/
[8] https://golang.org/
[9] https://www.rust-lang.org/
[10] https://bastienvigneron.medium.com/pourquoi-jutilise-go-41bba48dfe47
[11] https://bastienvigneron.medium.com/retour-dexpérience-sur-rust-après-6-mois-20de056d3e3f
[12] https://benchmarksgame-team.pages.debian.net/benchmarksgame/index.html
|