ChatGPT : comment ça marche ?
Pierre-Carl Langlais
Tout-le-monde en parle : chatGPT révolutionne l'enseignement, la programmation, la propagande, le marketing, la politique... Et pourtant, qui est chatGPT ?
Tout d'abord deux modèles différents, souvent confondus.
GPT c'est Generative Pre-trained Transformer 3, un modèle géant de prédiction de texte entraîné par OpenAI sur 500 milliards de mots. GPT-3 est non seulement capable d'écrire correctement dans plusieurs langues mais c'est aussi un modèle encyclopédique qui intègre un grand nombre de références au monde réel (personnes, événements, connaissances scientifiques) qu'il restitue plus ou moins bien. GPT-3 existe déjà depuis environ deux ans mais n'a jamais été ouvert au grand public. Et cela pour des raisons de coût mais aussi, surtout de risques : GPT-3 n'a pas vraiment d'inhibition et peut générer n'importe quoi tant que le texte est superficiellement cohérent.
ChatGPT est aussi basé sur InstructGPT, un modèle conversationnel « d'apprentissage renforcé par retours humains » (Reinforcement Learning from Human Feedback ou RLHF). Il s'agit d'une version "redressée" de GPT-3 créée à partir de l'annotation de textes générés. Le modèle incorpore toute une série de récompenses (« rewards ») et de pénalités qui jouent plusieurs fonctions : renforcer la cohérence du texte généré, éviter les contre-vérités flagrantes, mais aussi modérer par anticipation de potentielles dérives toxiques. Parmi tout l'univers des réponses linguistiquement correctes que GPT-3 pourrait générer, chatGPT opte pour celles qui sont le plus correctes dans le contexte d'un chat : c'est ce qu'on appelle l'alignement (« AI alignment »). Sur la base de ce même principe, chatGPT refuse aussi parfois carrément de répondre.
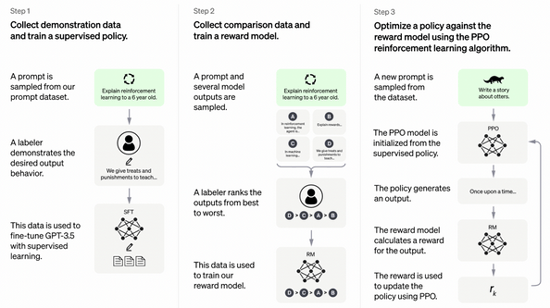
Schéma du « modèle conversationnel » (RHLF) de chatGPT.
L'articulation des deux modèles n'est pas très claire. Ils semblent avoir été déjà fusionnés dans la nouvelle version de GPT-3 utilisé par chatGPT, GPT 3.5 (aussi appelé text-davinci-003). Mais chatGPT utilise en plus un (ou plusieurs ?) modèles conversationnels plus légers en amont et en aval. S'y ajoute enfin des filtres de modération indépendants qui empêchent par exemple de poser des questions inconvenantes.
Néanmoins la distinction entre modèle textuel et modèle conversationnel est fondamentale pour comprendre comment fonctionne chatGPT :
Le modèle linguistique n'est pas actualisé et ne se nourrit pas des suggestions des utilisateurs. L'entraînement des modèles GPT est très coûteux et ne sera renouvelé qu'une fois par an environ (donc pour maintenant, on attend GPT-4). C'est la raison pour laquelle chatGPT ne ferait pas de références au monde actuel après 2021 [1]. Le modèle conversationnel continue de s'affiner en fonction du retour des utilisateurs : toutes les 3-4 semaines en moyenne, OpenAI améliore l'alignement du modèle avec les intentions des utilisateurs ou de la plate-forme. Si le modèle textuel ne change pas, le modèle conversationnel opte pour des générations de meilleures qualités et, inversement, pénalise davantage les générations malvenues. La dernière version en date du 30 janvier, améliore ainsi la « factualité » de chatGPT ou, plus prosaïquement, pénalise davantage les « hallucinations » (c'est le terme consacré pour désigner les générations purement imaginaires). Le modèle conversationnel semble aussi disposer de sa propre « mémoire » ce qui lui permet de tenir des conversations plus longues que le modèle linguistique.
Au-delà des deux modèles, chatGPT est un amoncellement de strates, de morceaux de codes et de concepts qui marque l'aboutissement de 70 ans de recherches en linguistique, en informatique. Au fond, le meilleur moyen de comprendre chatGPT c'est encore d'en retracer l'histoire. Essayons de dénouer un peu tout ça.
1. Le principe fondateur : la statistique sémantique
En janvier 1954, l'ordinateur IBM de l'université Georgetown tourne à plein régime [2]. Chercheurs, journalistes et responsables politiques assistent à la première démonstration publique d'un traducteur automatique : en quelques instants, le programme parvient à traduire parfaite quelques phrases de russe en anglais. En réalité, la démonstration est truquée. Le programme ne connaît qu'un vocabulaire réduit de 250 mots en russe et en anglais et, surtout, seulement quelques règles de grammaire. Les phrases ont été commodément choisies en amont pour être correctement restituées.
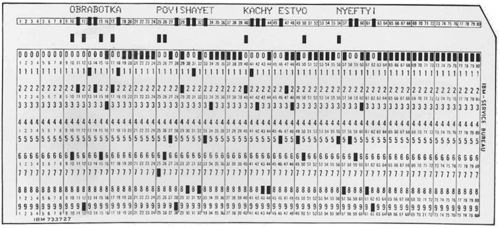
L'une des fiches créés pour l'expérience de traduction automatique de Georgetown en 1954. La phrase en russe représente l'input initial.
Malgré ce truc, l'expérience suscite de grandes espérances. Les premiers ordinateurs sont tout auréolés du déchiffrement d'Enigma. Et si au fond, les langues n'étaient que des codes comme les autres ? L'allemand ou le russe n'est-il que de l'anglais crypté ?
Les spécialistes de l'informatique sont sceptiques. En 1947 le mathématicien Warren Weaver écrit au père fondateur de la cybernétique, Norbert Wiener. Il envisage de créer un programme de traduction automatique universel pour assurer la « paix dans le monde » (éventuellement avec le soutien financier l'UNESCO). Cet échanges est publié en 1949 par Weaver dans un court « Mémorandum » [3]. Malgré sa nature un peu décousue, ce texte pose les bases d'une théorie fondamentale qui est directement à l'origine de chatGPT : la statistique sémantique.
Norbert Wiener constate que les solutions « naïves » de traduction par ordinateur ne sont pas généralisables. Les mots ont trop de sens différents : « Je redoute franchement que les frontières entre les mots de différentes langues sont trop vagues et les connotations émotionnelles sont trop étendues pour réaliser un quelconque projet de "mécanisation" de la langue »;. Weaver émet alors l'hypothèse que l'ordinateur ne devrait pas seulement traiter les mots d'une manière isolées. Il faudrait tenir compte du contexte ou même déjà du « micro-contexte », celui des voisins immédiats du mot dans la phrase :
|
Si nous lisons un mot dans un livre en isolation à travers un masque opaque (...) il est impossible de déterminer sa signification (...) Si maintenant, nous élargissons le masque opaque, de telle manière que nous ne voyons pas seulement le mot, mais aussi un nombre N de mots de chaque côté, si N est suffisamment large, nous pouvons sans ambiguïté trouver la signification du mot.
Warren Weaver, « Mémorandum », p. 8. |
Ce N correspond à ce qu'on appellerait aujourd'hui une « fenêtre contextuelle » (context window). Au début des années 2010, les premiers modèles courants de texte par réseaux de neurone utilisaient une fenêtre contextuelle d'une dizaine de mots. Dans GPT 3.5 cette fenêtre a été élargie à environ 3 000 mots [4] (ou 4 000 « tokens »).
La fenêtre contextuelle repose sur l'hypothèse d'une statistique sémantique ou sémantique distributionnelle [5] : le sens procède de la position relative des mots les uns avec les autres. Nous en faisons tous l'expérience en lisant dans une langue étrangère ou un texte un peu ancien. Souvent, il n'est pas nécessaire de consulter un dictionnaire pour saisir une définition approximative d'un mot ou d'un usage inusité. Il y a suffisamment d'indices dans le texte lui-même pour comprendre qu'il s'agit par exemple d'un lieu, d'un instrument ou d'une action.
2. Un espace de significations : les « embeddings »
En 1949, la sémantique distributionnelle n'est pas une hypothèse totalement originale. On l'a trouve sous d'autres noms ou d'autres approches chez la plupart des grands théoriciens linguistiques de la période, dont Roman Jakobson. Seulement pour Weaver ce n'est pas une observation générale du comportement linguistique, mais un problème à résoudre computationnellement.
Weaver, comme tous les chercheurs qui se pencheront sur le sujet jusqu'aux années 2010, est immédiatement confronté à un écueil majeur : même en se limitant au vocabulaire le plus basique (par exemple quelques milliers de mots), il existe des milliards et des milliards de combinaisons possibles. Indépendamment des limitations techniques des ordinateurs de 1949, recenser toutes ces possibilités est un travail absolument inconcevable.
À partir des années 1980, plusieurs projet de recherche théorique et appliquée ont tenté de simplifier ces réseaux de co-occurrences massifs à partir de l'analyse matricielle. Les corpus sont transformés en tableaux géants associant un mot à un document (ou un mot à un mot). Puis plusieurs algorithmes peuvent être utilisés pour simplifier ce corpus en réduisent l'ensemble des occurrences possibles à un nombre prédéfini de dimensions (c'est la « décomposition matricielle »). La compression d'image est un assez bon analogue pour comprendre ce processus. Une image publiée un format « jpeg » est beaucoup moins volumineuse, simplement parce qu'elle ne conserve pas les pixels d'origine mais une série de paramètres et de poids permettant de recomposer l'image (c'est le coding de Huffman [6]).
Cette approche est qualifiée d'analyse sémantique latente [7] (ou indexation sémantique latente pour son versant plus appliqué). Elle est dite « latente » en raison de sa capacité à rapprocher des termes utilisés similairement même lorsqu'ils n'apparaissent jamais ensemble dans le même texte. C'est typiquement le cas des synonymes : « maison » et « habitation » vont rarement figurer dans la même phrase mais ont les mêmes voisins et, si elle est concluante, l'analyse sémantique latente devrait rapprocher les deux termes.
Aujourd'hui ces dimensions simplifiées sont qualifiés d'« embeddings » [8] ou plongement de mots. Pour simplifier, on peut considérer les embeddings comme des coordonnées dans un espace sémantique partagé : plus les mots sont « proches » dans cet espace et plus il vont avoir le même sens et le même principe peut s'appliquer aussi aux documents. Dans ce cadre, l'analyse du texte devient aussi une analyse spatiale : la similarité se mesure avec des rapports géométriques (en particulier, la similarité « cosine »). Ce tournant spatial affecte l'ensemble des corpus traités par l'intelligence artificielle. Texte, image, son, vidéo : tout est un embedding aujourd'hui. La génération d'une image par du texte est fondamentalement une opération de conversion des embeddings du texte en embeddings visuels.
ChatGPT procède encore de cette manière. Chaque « mot » généré est le résultat d'une exploration spatiale qui tient à la fois compte des voisins immédiats du mot (qui vont notamment déterminer sa syntaxe), du sens général de la conversation (la fenêtre contextuelle de 3 000 mots) et de tout le vaste imaginaire des mots possibles dans cette langue.
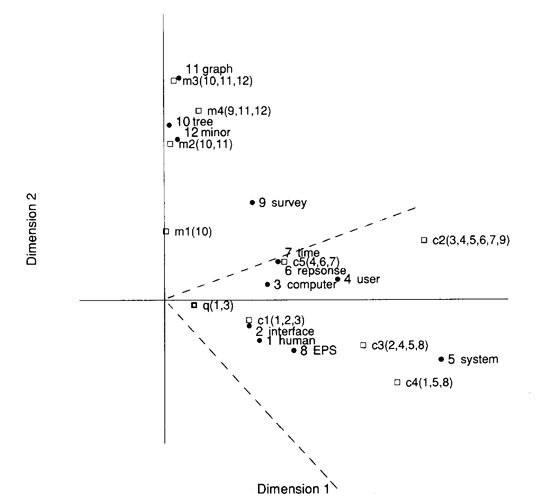
Projection d'analyse sémantique en deux dimensions dans
« Indexing by Latent Semantic Analysis » (1990, p. 397).
L'analyse sémantique latente est cependant toujours contrainte par la taille du corpus. S'il est possible de construire un tableau de cooccurrence pour un ensemble de quelques milliers de textes, cela devient rapidement impraticable à grande échelle. Pour l'ensemble de Wikipédia anglais (qui jusqu'à récemment était le corpus de référence pour l'IA appliquée au texte), cela représenterait un tableau extrêmement clairsemé de 5 millions de documents d'un côté et de plusieurs centaines de milliers de mots de l'autre (même si on se limite uniquement aux termes un peu fréquents), soit environ 500 milliards de données. Même aujourd'hui seul un superordinateur serait capable de traiter un corpus de taille...
3. Le modèle : un réseau de neurone
Dans son Mémorandum visionnaire publié en 1949, Warren Weaver mentionne incidemment la meilleure solution technique pour encoder les milliards de relations contextuelles d'un mot vers un autre : un réseau de neurone. Malgré son ascension fulgurante ces dernières années, le réseau de neurone est aussi une technologie ancienne, théorisée par McCulloch et Pitts [9] dès 1943. Weaver s'intéresse alors particulièrement à leurs capacité d'actualisations : les réseaux de neurones peuvent réévaluer les données initiales à la lumière de nouvelles observations grâce à une boucle de rétroaction (feedback loop). Sur cette base, il pourrait être possible de traduire des textes dotés d'une forte logique interne – ce qui exclut, pour Weaver, la traduction littéraire.
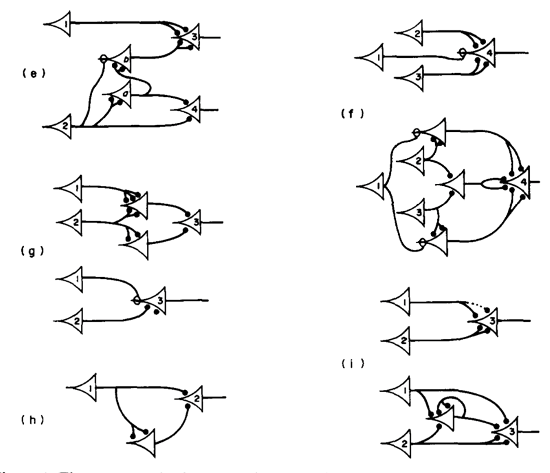
Les réseaux de neurones de 1943 (McCulloch & Pitts, p. 105)
- déjà envisagés par Warren Weaver et Norbert Wiener
pour solutionner leurs problèmes de traduction automatique.
Weaver ne soupçonne pas que les réseaux de neurones sont des algorithmes de « compression » extrêmement efficaces. Ils parviennent aujourd'hui à réduire des milliards de milliards de relations possibles en un nombre limité de paramètres et de poids. Le modèle de génération d'image Stable Diffusion est un exemple parfait : un corpus initial de 170 millions d'image est transformé en un modèle de seulement 2 gigaoctets, soit une dizaine d'octets par image. Évidemment, les réseaux de neurones ne peuvent pas recréer les productions originales en dehors de quelques cas particuliers, mais ils conservent une mémoire des représentations abstraites et des styles, ce qui permet ensuite de générer un nombre indéfini d'images nouvelles.
Du fonctionnement théorique à l'application pratique il y a un pas énorme. Les réseaux de neurones sont très coûteux en opérations computationnelles, en grande partie à cause de leur capacité d'actualisation. La recherche dans ce domaine reste quasiment « congelée » jusqu'aux années 1990, quand les infrastructures techniques deviennent suffisamment performante pour tester empiriquement des architectures jusqu'ici essentiellement théoriques.
En 2013, une équipe de chercheurs de Google sous la direction de Tomas Mikolov publie une méthode révolutionnaire qui va se répandre comme une traînée de poudre : word2vec [10]. word2vec s'appuie sur un réseau de neurone simple à une seule couche (c'est du shallow learning par opposition au deep learning plus communément utilisé aujourd'hui). Concrètement il n'est pas nécessaire de stocker en amont un tableau gigantesque de cooccurrence. word2vec définit les coordonnées sémantiques des mots au fil de l'eau, en « lisant » le corpus au fur et en prenant 10-15 termes à la fois (c'est la taille de sa « fenêtre contextuelle »). Dans l'un de ses exemples de démonstration, word2vec utilisait ainsi un corpus de 100 millions de mots extrait de Wikipédia. L'entraînement de ce corpus peut être fait sur un simple ordinateur personnel.
Cette innovation technique entraîne toute une série d'innovations conceptuelles. Mikolov s'est formé en République Tchèque et s'inscrit dans la tradition de l'analyse linguistique structurelle de Roman Jakobson. Il perçoit immédiatement tout le potentiel de la statistique sémantique appliquée à de très larges corpus. Il est possible non seulement de recouvrer des synonymes mais aussi d'identifier des relations de genre (du féminin au masculin), d'abstraction, de fonction ou de situation géographique, simplement en se baladant dans l'espace sémantique créé par word2vec. L'un des exemples cité dans l'article originel de Mikolov porte ainsi l'identification des capitales sur la base du nom du pays :
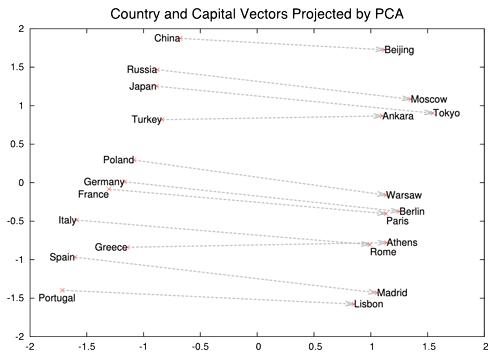
Identification des capitales à partir du nom d'un pays. La relation pays => capitale, correspond à une distance précise dans l'espace sémantique des « word embeddings ».
Word2vec ne fait qu'appliquer les principes élémentaires de la statistique sémantique. En 2014, les linguistes Omer Lévy et Yoav Goldberg constatent [11] que le réseau de neurone « léger » n'est qu'un outil d'optimisation. Toute les opérations effectuées à partir des embeddings pourraient être réalisées avec des tableaux géants de cooccurrences (ce que fait d'ailleurs un autre programme créé par Stanford, Glove).
Le recours au réseau de neurone représente néanmoins une simplification massive. Rapidement, il apparaît que les word embeddings peuvent être transférés entre les langues. Le réseau des relations sémantiques n'est pas notablement différent entre les langues d'une même famille linguistique et il suffit d'un petit nombre d'alignements prédéfinis (par exemple sur la base d'un dictionnaire) pour les recouvrer. À partir de 2015, une version améliorée de word2vec, fasttext [12], publie des embeddings dans près de trois cents langues, dont 44 langues « alignées » [13].
Ce principe de transfert linguistique est fondamental pour chatGPT. La génération de texte en français se nourrit non seulement des corpus francophones mais aussi du transfert de l'espace sémantique e toutes les autres langues, ce qui permet de faire allusion à un grand nombre de faits et d'informations qui ne seraient pas forcément présents dans le corpus initial.
4. Lire le texte attentivement : les « transformers »
Word2vec a immédiatement trouvé son utilité en analyse de corpus – mais beaucoup moins pour la génération de texte. Ce n'est pas très surprenant. Dans sa phase d'apprentissage, word2vec traite tous les mots de sa fenêtre contextuelle en vrac (c'est qu'on appelle un sac de mot ou « bag of words ») : l'ordre n'a aucune importance. Par conséquent, si le modèle fonctionne très bien pour recouvrer le sens d'un mot en particulier, il n'est pas vraiment censé compléter ou générer une phrase, faute d'une compréhension générale de la syntaxe.
D'autres réseaux de neurones se prêtaient mieux à la génération de texte. Les réseaux « séquentiels » (comme les LSTM) conservent une mémoire agrégée de tous les mots immédiatement antérieurs. Seulement, plus la phrase antérieure (ou la fenêtre contextuelle) est longue et plus cette mémoire va se dégrader : c'est le problème de la disparition du gradient [14]. Ces réseaux de neurones ressemblent un peu à une personne peu attentive qui attrape au passage des bribes d'une conversation. Tant que la discussion n'est pas très complexe, il est possible de la reconstituer approximativement. Au-delà d'un certain seuil de complexité, on ne comprend plus rien.
Les modèles « transformers » apparaissent en 2017 sur la base d'un principe relativement simple : « tout ce dont vous avez besoin, c'est de l'attention » (« All you need is attention » [15]). Au lieu de se limiter à une lecture flottante de ce précède et d'en retirer une vague notion générale du sujet du texte, les modèles transformers modélisent les interactions entre les mots précédents. Ils ont une compréhension intuitive de la syntaxe et de la composition de la phrase qui fait défaut dans tous les modèles qui l'ont précédé. Évidemment, cette modélisation est complexe : les réseaux de neurones légers utilisés par word2vec laissent place à de l'apprentissage profond (« deep learning »).
Visualisation du mécanisme d'attention des transformers dans BertViz :
chaque mot est pris dans un réseau de relation avec d'autres mots.
Ce mécanisme d'attention change complètement les règles de l'interaction avec l'IA ainsi que sa géographie sémantique sous-jacente. Le modèle est naturellement conçu pour réagir à un texte pré-existant ou le compléter – ce que l'on appelle un prompt. Au lieu de créer un jeu de coordonnées sémantique (ou « embedding ») pour chaque mot, il y a maintenant des coordonnées pour chaque occurrence précise du mot. Par conséquent, il devient possible d'étudier précisément l'emploi de certaines formules syntaxiques, ce qui aurait été impossible avec word2vec. En 2020, Lauren Fonteyn a pu analyser l'évolution de l'usage de l'expression anglaise « to be about » en projetant un grand nombre de verbatims dans le même espace sémantique.

Les différentes acceptions de « to be about » en anglais :
les clusters identifiés par BERT correspondent presque parfaitement
à l'interprétation linguistique (Fonteyn, 2020).
5. Toute la culture dans un espace : les grands modèles linguistiques
En raison de leur sophistication, les modèles transformers ne peuvent pas être créés avec un équipement informatique classique. À partir de 2018, Google commence à mettre à disposition toute une série de modèles « pré-entraînés » sous le nom de BERT [16] (du nom du protagoniste de la série de marionnettes des années 1990 Sesame Street).
BERT ouvre une nouvelle ère : celle des « grands modèles de langue » (Large Language Model). Les premières versions, Bert Base et Bert Large reposent sur un large corpus : une bonne partie de Wikipédia (2,5 milliards de mots) et une collection composite de livres appelé Books2 (800 millions de mots). L'espace sémantique ainsi modélisé est documenté par 110 millions de paramètres (pour Bert Base) et 340 millions de paramètres (pour Bert Large). La phase d'entraînement représente un coût matériel d'environ 7000$ (correspondant aux coûts d'acquisition et d'usure des infrastructures en GPU).
Ces investissements étaient inédits en 2018. Ils vont être très rapidement dépassés : la création de BERT ouvre une compétition massive. Corpus, paramètres, architecture : tout grossit à vitesse grand v. Si toutes les grandes plates-formes occupent le terrain (Google, Facebook et Microsoft), c'est finalement un nouveau venu qui emporte la mise : OpenAI. Cette petite structure non-commerciale accomplit un grand saut dans l'inconnu en 2019 : son propre modèle transformer, GPT [17] est entraîné sur un corpus immense, WebText. Il s'agit d'une sélection de l'archive du web Common Crawl [18] : n'ont été retenus que les liens partagés (et likés) sur Reddit. Le coût réel de GPT-2 est inconnu mais dépasse probablement le million de dollars.
Par rapport à l'ensemble des modèles transformers, GPT-2 n'est pas très original. Seulement, le passage à l'échelle change tout. Non seulement, GPT-2 écrit des textes beaucoup plus crédibles, mais il s'agit aussi d'un modèle encyclopédique. Il contient un large répertoire de « faits » scientifiques ou historiques dans lequel il puise avec plus ou moins d'adresse. GPT-2 n'a pas seulement créé un espace sémantique mais aussi un vaste espace culturel latent.
À la différence des modèles exclusivement linguistiques qui l'ont précédé GPT-2 peut prétendre formuler des « faits » ou des informations. Sa mémoire encyclopédique, principalement basée sur Wikipédia et quelques autres sources académiques, contient un grand nombre de référence au monde réel. Seulement, il n'y a pas de garantie qu'elles soient parfaitement restitué.
L'épistémologie de GPT est probabiliste : plus un énoncé est présent dans le corpus d'entraînement et plus il a de chance d'être correctement restitué. C'est ainsi que chatGPT affirmera généralement que Napoléon a perdu à Waterloo tant cette information a pu être ressassée dans le corpus d'origine. Seulement dès qu'un énoncé est rarement présent où dès que le prompt d'origine prend une direction imprévue, le modèle peut facilement se perdre dans une série d'hallucinations.
Un exemple de l'épistémologie probabiliste de chatGPT :
sur une question standard de culture générale, la réponse est presque toujours exacte.
Sur un sujet de niche que je maîtrise relativement bien (l'histoire de la presse au 19e siècle), chatGPT brode des faits vraisemblables à première vue mais qui n'ont jamais existé.
GPT-3 marque encore un nouvel élargissement des capacités encyclopédiques de GPT-2. Le nombre de paramètre du modèle est multiplié par 100 et passe de 1,5 milliards à 175 milliards. Cela n'a pas vraiment d'incidence sur l'intelligence du modèle contrairement à ce qu'on peut lire un peu partout, mais sur sa mémoire collective : il parvient à faire des allusions ou des références à des informations « rares » mentionnées uniquement quelques fois dans le vaste de corpus de près de 500 milliards de mots.
6. L'inconscient des bots : l'IA en quête d'alignement
De GPT-3 à chatGPT, l'évolution est d'un autre ordre : vers le déploiement d'un modèle conversationnel capable de contrôler et "aligner" les générations du modèle linguistique et encyclopédique.
C'est une préoccupation ancienne. Déjà en 1960, Norbert Wiener s'inquiétait du futur de la coopération entre humains et agents intelligents : si nous en venons à déléguer des tâches critiques à des « agents mécaniques », nous devons « nous assurer que les objectifs de la machine sont bien les nôtres et pas juste une représentation attrayante (colourful imitation) de nos intentions » [19]. Pour reprendre la terminologie de Wiener, tous les textes générés par GPT-3 sont des « représentations attrayantes ». Le modèle flotte librement dans l'espace des significations sémantiques, sans aucune boussole morale.
Si l'ouverture de chatGPT a été un tel choc, c'est aussi parce que le grand public a été soigneusement mis à l'écart du long processus de perfectionnement des générateurs de texte. Plusieurs accidents industriels ont convaincu les grandes plates-formes de limiter l'accès autant que possible à des usages professionnels ou scientifiques. En mars 2016, « Tay » [20], un chatbot de Microsoft s'est rapidement mis à produire des messages racistes et sexistes après quelques heures d'activité sur Twitter. Twitch vient tout juste de suspendre [21] une émission entièrement générée dans le style de Seinfeld, « Nothing Forever » suite à la génération accidentelle d'un texte potentiellement transphobe (l'interprétation est discutée...). De fait, l'agent conversationnel de référence des années 2010 n'est pas Tay ou une version dérivée de Bert : c'est Siri, le robot d'Apple étroitement contrôlé par un système de règles rigides et qui pourrait avoir été déjà développé dans les années 1960.
Depuis 2019, un nouveau champ de recherche a rapidement émergé sur le « renforcement humain » de l'apprentissage automatisé (Reinforcement Learning from Human Feedback). Par opposition aux problèmes éthiques finalement assez théoriques soulevés par Wiener, la question devient très pratique. Les grands modèles de langue génèrent du texte crédible mais qui n'est pas forcément vrai, fiable ou éthique.
Évidemment aucun générateur de texte n'est parvenu à surmonter ces difficultés. Seulement, en raison de la qualité du texte et de sa capacité de conviction, le risque de dérives est considérablement plus élevé. Produire un texte de qualité représente un certain coût. J'en ai vraiment pris conscience en contribuant activement à Wikipédia : environ 80-90 % des canulars et des vandalismes se détectent en quelques secondes, simplement à partir de la forme du texte, qui n'adhère pas au norme implicite de la rédaction encyclopédique. Avec GPT-3, créer un faux article convaincant de Wikipédia prend aussi quelques secondes.
De plus les modèles de langue sont particulièrement bon pour identifier des représentations sociales latentes, pas forcément explicitement avouées. Déjà en 2016, une étude [22] montraient que les word embeddings recréaient spontanément des représentations sexistes (un programmeur est exclusivement masculin), simplement parce que l'espace sémantique simplifie et radicalise des conceptions sociales communément partagées.
Nous l'avons déjà évoqué au début de l'article : le renforcement humain repose sur une classification a posteriori de générations de texte. Heureusement, il n'est pas nécessaire de classer des centaines de millions de textes pour obtenir des résultats valables. Certains comportements "désirables" du modèle sont déjà présents à l'état latent, aussi parce que le corpus d'entraînement a été sélectionné sur cette base. Dans Common crawl la grande majorité des textes sont de nature encyclopédique ou scientifique et on trouvera peu de contenus ouvertement conspirationnistes. D'après une synthèse de HuggingFace [23] obtient des résultats relativement probants à partir de 50 000 exemples annotés.
Cela représente quand même beaucoup de travail. Mon hypothèse personnelle est que chatGPT a été conçu comme un moyen très efficace de collecter du « digital labor ». Le modèle conversationnel a été d'abord « entraîné » par des annotateurs de pays en voie de développement, en particulier au Kenya [24]. Aujourd'hui environ dix millions d'utilisateurs uniques génèrent des dizaines de millions de textes par jours et envoient peut-être des dizaines de milliers de signalements. Ce n'est évidemment pas gratuit. Pour faire tourner chatGPT à cette échelle, OpenAI dépense probablement des millions d'euros par mois. Seulement, au-delà de la publicité énorme, OpenAI a réussi à collecter un corpus considérable d'annotations qui sera sans doute difficile à répliquer : quand les chatbots de ses concurrents (Google, Baidu, etc.) seront disponibles gratuitement, l'effet de nouveauté se sera un peu émoussé...
7. Reprise et coda
Dès lors récapitulons. Que se passe-t-il lorsque chatGPT génère un nouveau mot ?
Le modèle tient d'abord compte de toute la conversation antérieure, dans la limite fixée par la fenêtre contextuelle du modèle GPT 3.5 (environ 3 000 mots). Il peut à la fois faire référence à des éléments déjà mentionnés mais aussi s'inscrire dans la continuité thématique ou stylistique de la discussion. Tous les mots n'ont cependant pas le même poids et grâce au mécanisme d'attention intégré dans les modèles transformers, chatGPT va accorder beaucoup plus d'importance aux mots immédiatement antérieurs (qui conditionnent la syntaxe de la phrase) ou à des passages plus anciens qui ont une incidence directe sur la formulation du mot (ce qui permet par exemple de faire revenir le nom d'un protagoniste lors de l'écriture d'une histoire). La barrière de la langue n'est pas un problème pour chatGPT. On peut passer indistinctement du français à l'anglais puis à l'italien : ces différentes langues sont "alignées" et puisent dans un répertoire sémantique commun.
Tout ceci pose le contexte initial et un certain univers de possibilités. Cependant, chatGPT reste relativement libre de puiser dans une mémoire sociale et collective bien plus vaste. ChatGPT arpente cette mémoire comme un espace – en vérité, la fameuse métaphore rhétorique des lieux de mémoires [25] n'a jamais été aussi appropriée. Comme un rhéteur de la Renaissance, chatGPT se perd dans un palais de mots. Il va généralement prendre les chemins les plus courants mais il peut aussi lui arriver de s'égarer. En vérité, la direction prise est imprévisible : chagGPT n'est pas déterministe. Il y a toujours une part de hasard ou d'inspiration dans ses pérégrinations.
À la différence des modèles GPT et GPT 3.5, l'imaginaire de chatGPT n'est pas totalement débridé. Il doit passer d'abord le seuil de son inconscient : ce système de « feeback » récompense ou pénalise les générations de mots qui ne s'accordent pas aux attendus de la conversation, soit parce que ces mots seraient inconvenants, soit parce qu'ils seraient inexacts. Je pense que ce dispositif fonctionne également comme une mémoire étendue et permet ponctuellement à chatGPT de se « souvenir » de mots ou de situations qui excèdent sa mémoire contextuelle normale limitée à 3000 mots.
Bien évidemment, il reste encore beaucoup de zones d'ombre. Un peu plus de deux mois après le lancement de chatGPT, OpenAI n'a toujours rien publié. On doit se contenter de recoller les morceaux à partir des questions-réponse sur le site, ou de descriptions assez génériques de GPT-3.5 ou d'InstructGPT. Cela pourrait rapidement changer. La concurrence va s'intensifier. Dans quelques semaines, Google devrait ouvrir l'accès à son propre chatbot, Bard [26].
Les évolutions les plus intéressantes vont peut-être venir d'ailleurs.
ChatGPT a montré d'emblée le potentiel des grands modèles de langue dans plein de domaines mais on est encore loin d'un usage véritablement professionnel. Je m'attends à une déferlante rapide de chatGPT spécialisés, entraînés sur une tâche relativement précise, à l'image des modèles créés en France par LightOn [27] : l'implication en amont des utilisateurs à venir de ces modèles sera probablement déterminante pour garantir un bon « alignement" avec l'univers social et professionnel auquel il sera destiné.
Et, les grands générateurs de texte vont peut-être prochainement connaître sa révolution open source. Pour l'instant, chatGPT (et GPT-3) est un peu naturellement protégé par sa taille : il n'est pas possible de recréer ni même de faire tourner un modèle de cet ampleur dans un contexte non-commercial. Cela ne durera peut-être pas. Les générateurs d'images ont déjà connu des optimisations massives : en 2021, il me fallait plus d'une heure pour créer une image relativement floue sur Google Colabs. Aujourd'hui, Stable Diffusion génère de véritables photographies imaginaires en moins de vingt seconde sur mon ordinateur personnel. La même équipe de recherche à l'origine de Stable Diffusion envisage aujourd'hui de créer une version libre de chatGPT beaucoup plus économe (environ 24 go de mémoire vive : c'est au-delà des capacités de la plupart des ordinateurs personnels mais on n'en est quand même plus très loin).
Pierre-Carl Langlais
Docteur en sciences de l'information et de la communication
Chercheur associé GRIPIC
Paru le 7 février 2023 sur Hypothèse.
https://scoms.hypotheses.org/1059
Cet article est sous licence Creative Commons (selon la juridiction française = Paternité - Pas de Modification).
http://creativecommons.org/licenses/by-nd/2.0/fr/
NOTES
[1] Enfin, je pense que des documents de l'année 2022 sont présents dans GPT-3.5, comme le modèle n'a été publié qu'en novembre 2022, mais cela reste parcellaire et il est plus commode pour OpenAI de communiquer sur une coupure nette après 2021.
[2] https://en.wikipedia.org/wiki/Georgetown–93IBM_experiment
[3] https://aclanthology.org/1952.earlymt-1.1.pdf
[4] https://help.openai.com/en/articles/6787051-does-chatgpt-remember-what-happened-earlier-in-the-conversation
[5] https://en.wikipedia.org/wiki/Distributional_semantics
[6] https://en.wikipedia.org/wiki/Huffman_coding
[7] https://en.wikipedia.org/wiki/Latent_semantic_analysis
[8] https://en.wikipedia.org/wiki/Word_embedding
[9] https://www.cs.cmu.edu/~./epxing/Class/10715/reading/McCulloch.and.Pitts.pdf
[10] https://proceedings.neurips.cc/paper/2013/file/9aa42b31882ec039965f3c4923ce901b-Paper.pdf
[11] https://proceedings.neurips.cc/paper/2014/file/feab05aa91085b7a8012516bc3533958-Paper.pdf
[12] https://github.com/facebookresearch/fastText
[13] https://fasttext.cc/docs/en/aligned-vectors.html
[14] https://en.wikipedia.org/wiki/Vanishing_gradient_problem
[15] https://arxiv.org/abs/1706.03762
[16] https://arxiv.org/pdf/1810.04805v2.pdf
[17] GPT est un modèle dit « génératif » au sens où il n'est pas initialement entraîné sur une tâche précise. Même si l'architecture diffère, la conception générale du modèle n'est pas très différente de BERT.
[18] https://commoncrawl.org/
[19] Norbert Wiener, Some Moral and Technical Consequences of Automation, p. 88.
[20] https://en.wikipedia.org/wiki/Tay_( bot)
[21] https://www.reddit.com/r/WatchMeForever/comments/10v22xk/why_the_boy_was_banned/
[22] https://proceedings.neurips.cc/paper/2016/file/a486cd07e4ac3d270571622f4f316ec5-Paper.pdf
[23] https://huggingface.co/blog/rlhf
[24] https://time.com/6247678/openai-chatgpt-kenya-workers/
[25] https://fr.wikipedia.org/wiki/Méthode_des_loci
[26] https://blog.google/technology/ai/bard-google-ai-search-updates/
[27] https://www.lighton.ai/fr
|