|
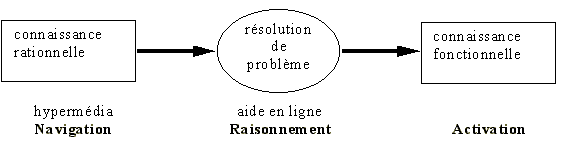
À quels types d'apprentissages André Tricot INTRODUCTION Depuis 1987, les logiciels hypertextes et hypermédia ont soulevé un certain enthousiasme, notamment dans le domaine de l'enseignement. Les deux colloques français « Hypermédias et apprentissages » [1] ont réuni des enseignants et des chercheurs qui étaient engagés non seulement dans la réflexion mais aussi dans la création de logiciels hypermédia. Cet article propose un point sur la question de la pertinence de ces travaux [2]. La démarche proposée consiste dans un premier temps à essayer de « mettre à plat » certaines questions comme : Qu'est-ce qu'apprendre ? Qu'est-ce que l'ordinateur peut apporter à un apprentissage ? Qu'est-ce qu'un logiciel hypermédia ? Quels hypermédias dédiés à l'apprentissage existent ? Si toutes ces questions sont simples, les réponses le sont beaucoup moins. Il est même probable que certaines d'entre elles n'aient jamais de réponse définitive. C'est pourquoi je me bornerai à un discours de chercheur en psychologie cognitive (car l'enseignant et le créateur de logiciels pour l'apprentissage, qui doivent AGIR, ont nécessairement une réponse, même momentanée et vague, à ces questions). Dans un deuxième temps, je tenterai de rapporter des résultats expérimentaux récents et pour la plupart anglophones, les travaux francophones étant mieux connus, et probablement un peu lacunaires sur cet aspect, comme on le remarquait lors du 2e colloque (il faut bien entendu signaler l'exception de Jean-François Rouet, qui publiait ici même dans le n° 73 un article remarquable). Les éléments de réponse que je proposerai ne concerneront donc que des aspects très limités des questions posées. Comme ce papier prétend être une synthèse, il est assez court. De nombreuses références bibliographiques sont données en notes, ainsi que quelques précisions. QU'EST-CE QU'APPRENDRE ? Apprendre à partir de quoi ? Les chercheurs en psychologie cognitive se sont intéressés à l'acquisition de connaissances dans des contextes définis par ce qui est traité par le sujet : environnement physique, stimuli, exemples, exercices, problèmes, faits déclarés, règles... Ces différents contextes se recouvrent partiellement les uns les autres. Un des progrès de ces dernières années dans le domaine a consisté en l'analyse plus fine de ce qui est vraiment traité par le sujet, en mettant particulièrement en avant l'importance du « contexte » [3] dans ce type de traitement. En 1987, Anderson [4] faisait remarquer que ces contextes traditionnels de l'étude des apprentissages par les chercheurs en psychologie cognitive en occultaient un, celui-là même auquel sont confrontés les enfants six heures par jour pendant de longues années : l'enseignement. La démarche andersonnienne en la matière [5] consiste à élaborer des logiciels d'enseignement en conformité avec une théorie de l'acquisition de connaissances. Si les apprenants acquièrent ce à quoi l'on s'attendaient, alors on considère que la théorie n'est momentanément pas invalidée. On peut, grâce à cette démarche, apporter des modifications à la théorie, modifier localement le logiciel en conséquence, et expérimenter avec des apprenants à nouveau. Ainsi donc, à la fin des années 80, la psychologie cognitive rejoignait l'EAO pour s'en servir comme outil. L'EAO lui, pouvait déjà être muni de théories cognitives implémentées (LOGO par exemple). L'autre partie de cette question « apprendre à partir de quoi ? », est bien-entendu : à partir des connaissances antérieures. La psychologie cognitive a étudié le rôle fondamental de ces connaissances dès les années 70. La métaphore de la boite vide ou de l'enregistreur n'a plus cours depuis longtemps, chez (tous ?) ceux qui s'occupent d'enseignement. Apprendre quoi ? Les psychologues se sont aussi intéressés à l'acquisition de connaissances dans des contextes définis par ce qui est acquis par le sujet : réflexes, schèmes, « habiletés » (skills), schémas, connaissances déclaratives, connaissances procédurales, fonctionnalités... Ces différents contextes se recouvrent partiellement les uns les autres et sont, selon le cas, plus ou moins dépendants des contextes définis par ce qui est traité par le sujet. Concrètement, le travail des psychologues a notamment consisté à montrer que telle connaissance s'acquiert le plus souvent de telle façon. Sur la nature de ce qui est acquis, l'apport des modèles de la psychologie cognitive à notre connaissance des apprentissages est considérable. On peut remarquer aussi que l'école genevoise [6] est entrain d'opérer un recentrage de ses problématiques de recherche autour de cette question : étudier l'acquisition des fonctions plutôt que des structures. Apprendre comment ? On peut à un premier niveau, différencier l'apprentissage par le texte et l'apprentissage par l'action. On sait que les connaissances acquises à partir de ces deux types d'apprentissages sont globalement différentes (on pourra dire déclaratives pour le premier type d'apprentissage et procédurales pour le second type), mais qu'il y a des recoupements [7]. L'apprentissage par action [8] regroupe l'apprentissage par la découverte, les apprentissages instrumentaux et les apprentissages discriminatifs. L'apprentissage par la découverte recouvre les activités de catégorisation du problème, la construction de connaissances spécifiques à la situation, et la construction de connaissances générales. Une des problématiques actuelles à propos de ce type d'apprentissage concerne le transfert de connaissances que le sujet possède à une situation nouvelle. Des résultats obtenus en 1993 par des chercheurs sur l'analogie et sur le guidage dans l'exploration d'un espace-problème sont directement exploitables pour la conception de tuteurs. Thierry Ripoll [9] montre le rôle important d'indices « de surface » dans la récupération en mémoire d'un problème analogue, alors qu'avant on avait tendance à ne se focaliser que sur la structure du problème analogue. Karen Pierce [10] elle, met en évidence l'influence de la liberté d'exploration d'un espace problème sur la qualité du schéma [11] acquis, qui va permettre par la suite de traiter plus efficacement des situations-problème analogues non-isomorphes. Mais cette liberté d'exploration est coûteuse « cognitivement » et en temps. L'apprentissage par le texte Que sait-on sur l'apprentissage par le texte ? Essentiellement que les connaissances acquises sont majoritairement de type déclaratives, que les connaissances antérieures y jouent un rôle très important [12], et que la définition de variables dépendantes pose un problème, l'analyse classique des protocoles de rappel et reconnaissance étant peu pertinente [13]. L'apprentissage par le texte peut être considéré comme une activité de compréhension (notamment construction de structures conceptuelles), de mémorisation, et de production d'inférences (et non pas mémorisation de textes). Ici on conçoit la modification de la mémoire à long terme comme la modification de structures (réseaux sémantiques et schémas). En clair, si l'on travaille sur l'apprentissage par le texte, l'évaluation de l'apprentissage doit se faire sur trois niveaux : Le lecteur a-t-il compris ce qu'il a dans le texte (concepts, relations entre eux) ? Le lecteur a-t-il mémorisé ce qu'il y a dans le texte ? Le lecteur a-t-il compris ce qu'il n'y a pas dans le texte mais que l'on peut inférer ? L'évaluation ne peut pas se faire seulement au niveau du questionnement immédiat du lecteur, mais doit prendre en compte ce que le sujet peut traiter de nouveau et ce qu'il peut faire de nouveau. Les tâches d'apprentissage par le texte rapportées dans la littérature sur les hypertextes sont d'une grande diversité, et surtout, sont définies à des niveaux encore trop hétérogènes. On distingue par exemple les tâches de lecture pour écrire, pour comparer ou pour chercher des références [14] ; les tâches « répondre à des questions », « créer un carte conceptuelle qui représente les concepts et leurs relations », « enregistrer les informations utiles que l'on rencontre » [15] ; « prendre des notes en vue de la rédaction d'une dissertation », « répondre à un QCM » ou « juste regarder » [16] ; « chercher une occurrence ou plusieurs dans un ensemble de noeuds », « cocher puis rappeler tous les noeuds contenant telle occurrence » et « suivre les liens structuraux » [17]. QU'EST-CE QU'UN LOGICIEL HYPERMÉDIA ? Les hypertextes sont des systèmes informatiques où un ensemble de noeuds connectés par des liens gère un ensemble d'unités de texte [18]. Les hypermédias permettent de stocker des sons, des images, des animations, et du texte. Le nombre, la taille, la nature logique ou sémantique des noeuds, des liens et des unités de texte ne sont pas précisés. D'un point de vue technique, un hypertexte peut donc être à peu près n'importe quoi. Pour Ted Nelson, l'inventeur du terme, un hypertexte « est un ensemble de matériaux textuels ou picturaux interconnectés de telle façon qu'il serait impossible de les présenter ou de les représenter sur papier » [19]. Pour Vannevar Bush, l'inventeur du concept, un tel outil devait servir à stocker et à utiliser des documents en favorisant l'association d'idées [20]. Il y a donc trois façons (imprécises) de décrire des hypertextes : des points de vue de la technique, de la conception ou de l'utilisation. La description technique de ce qu'est un hypermédia n'est possible qu'à un niveau très général (imaginez que vous deviez décrire ce qu'est un livre en intégrant la Bible, le théâtre de Racine, le Tractatus Logico-Philosophicus, et un manuel d'histoire de 3°) : dans un hypertexte tout juste peut-on dire que le texte est « plein » et non-linéaire, que les liens et les noeuds sont nombreux. On peut aussi décrire certains aspects de systèmes (par exemple : « la base est de type hypertexte, mais munie d'un index »). Le point de vue de la conception : pour certains, l'hypertexte ne sert que d'interface, par exemple pour un système de gestion de bases de données objet [21]. Pour d'autres, l'hypertexte peut servir au stockage et à la recherche de documents, notamment dans le cadre de l'interrogation de bases de données « difficile » ou « imprécise » [22]. Pour l'équipe du MCC d'Austin ou celle de Cathe Marshall au Xerox PARC l'hypertexte prend toute sa valeur avec les travaux collaboratifs [23]. Enfin, les hypertextes sont de bons supports pour les oeuvres littéraires, ou plutôt dans le domaine des études littéraires et de la comparaison de documents [24]. Le point de vue de l'utilisation : malgré les progrès de la psychologie cognitive et de l'ergonomie cognitive, il est toujours assez difficile de décrire ce qu'un utilisateur fait avec de l'information. Mark Bernstein [25] a proposé de distinguer les cas où l'on voulait « extraire » précisément de l'information (typiquement l'interrogation d'une base de données), les cas où l'on voulait « confectionner » de l'information, soit la stocker, l'assembler, la raffiner, et l'entretenir pour la rendre disponible (typiquement l'EAO, l'informatique pour les entreprises) et enfin les cas où l'on voulait « jardiner « l'information, soit la travailler collectivement de façon continue pour des buts évolutifs (typiquement l'hypertexte rêvé par Engelbart ou Nelson). J'ai défendu ailleurs [26] l'idée que l'utilisation d'hypermédias avait trois avantages principaux. (a) facilité d'utilisation et de conception : l'utilisateur n'a pas à apprendre un langage d'interaction avec le système, ni les différentes fonctionnalités de celui-ci, pour l'utiliser. Par exemple, cette facilité permet de faire une recherche d'information sans passer par un langage de requête. Du côté de la conception, le concepteur voit « au fur et à mesure » ce qu'il fait et peut modifier localement ou globalement n'importe quel aspect de son système (programme ou interface). (b) liberté de choix : à chaque étape de l'utilisation le sujet effectue le choix du prochain noeud à voir. Ce choix peut être « sémantique » : l'utilisateur clique sur un bouton en fonction de sa signification. Ce choix peut aussi être « syntaxique » : l'utilisateur clique sur un bouton en fonction de sa fonction (noeud suivant, précédent, retour au départ, chapitre suivant...). Ainsi les hypermédias permettent de définir un contexte et des accès différents pour une même connaissance. Plus largement, ces systèmes permettent de représenter des connaissances sans contrainte logique, ni hiérarchique, ni ensembliste. (c) buts flous : la grande nouveauté des hypermédias comme « outils cognitifs » c'est de permettre aux utilisateurs d'avoir des buts mal définis. Dans l'activité de browsing (to browse = explorer, butiner, en quelque sorte « flâner parmi les données »), c'est en fonction des réponses du système que le sujet va cerner progressivement son problème. Les hypermédias sont susceptibles d'être intégrés dans des utilisations où la tâche de l'opérateur est « occasionnelle », mal connue ou mal définie par celui-ci, où le but peut être cerné par approximations successives : aide, recherche d'information, prise de décision, apprentissage, collaboration, etc. LES LOGICIELS HYPERMÉDIA POUR L'APPRENTISSAGE : qu'existe-t-il ? avec quels résultats ? Pourquoi a-t-on pensé, avec tellement d'enthousiasme, que les hypertextes seraient utiles à l'EAO ? Essentiellement à cause de la non-linéarité... qui est l'opposé de la linéarité! Comme tous les enseignants savent bien que la façon dont ils linéarisent leur enseignement peut gêner l'apprentissage, ou, du moins, que ce n'est pas cette linéarité qu'ils retrouvent dans les devoirs, alors la non-linéarité est apparu comme LA solution. Plus sérieusement Stanton & Stammers [27] ont déterminé quatre raisons pour lesquelles on peut utiliser un hypertexte en éducation : la possibilité de différents niveaux de savoirs prioritaires, encourager l'exploration, inciter les sujets à voir une sous-tâche comme une partie de la tâche principale, permettre aux sujets d'adapter le matériel à leur propre style d'apprentissage. Nous regrettons surtout que la non-linéarité ait emporté avec elle des questions comme : Qu'est-ce qu'apprendre ? Qu'apprend-t-on ? Qu'est-ce qu'une tâche d'apprentissage ? Il nous semble en effet qu'avant de parler d'hypertexte pour l'apprentissage, il fallait préciser de quel apprentissage on parlait. D'autre part, s'il existe une littérature très fournie sur les relations entre EAO et apprentissage par l'action, les hypertextes sont le premier moyen EAO de s'intéresser à l'apprentissage par le texte. Insistons à nouveau sur le fait que cela arrive en même temps que le regain d'intérêt de la psychologie cognitive pour l'enseignement et pour la recherche pédagogique [28]. En même temps il faut signaler des travaux qui utilisent plutôt l'idée d'hypertexte que l'hypertexte lui-même. Par exemple, pour gérer un ensemble de tuteurs intelligents [29] ou pour apprendre la lecture à des enfants sourds [30]. Quelques résultats expérimentaux Silva [31] a proposé à des élèves de collège une tâche de type « recherche d'information » exhaustive dans un système « musée électronique ». Le facteur expérimental manipulé était la « liberté de navigation », à quatre modalités : exploration séquentielle vs trois versions différentes d'exploration libre (a) libre sans plan (b) libre avec plan (c) libre avec plan interactif. A la fin de la visite ou quand le sujet considérait qu'il avait fini, on lui donnait un questionnaire sur le musée, avec quelques questions sur les contenus et quelques questions sur la localisation des éléments. Les résultats montrent que la mémorisation spatiale et des contenus est meilleure dans la condition (c) puis dans la (b), et que la condition (a) est quasiment équivalente à la condition exploration séquentielle. Dans une revue de littérature sur les avantages éventuels de la non-linéarisation de documents, Rouet [32] constate que l'efficacité de la non-linéarité varie selon (a) l'expertise des sujets (b) les caractéristiques de l'interface (c) ce que requiert la tâche. Il rapporte une recherche [33] où deux facteurs était croisés : F1 = (hypertexte / texte linéaire), F2 = (consigne « lire » / consigne « comprendre en vue d'un post-test »). Dans la condition hypertexte, les données sont organisées autour des concepts importants. 75 % de l'information secondaire est pourtant appelée par les lecteurs. La compréhension des concepts importants est meilleure. Le rappel libre est aussi meilleur, mais seulement pour la condition « consigne libre ». Les sujets « consigne libre » trouvaient la condition « hypertexte » plus difficile, plus lourde. Conclusion : l'hypertexte de sert à rien si l'objectif d'apprentissage n'est pas manifeste. Une autre étude [34] conclut assez classiquement sur l'avantage de structurer hiérarchiquement un hypertexte, pour une épreuve de compréhension. Dans cette expérience les sujets disposaient d'une table des matières qui reproduisait la structure hiérarchique : il semble que cela ait aidé à l'orientation. Jonassen & Wang [35] quand à eux, rapportent trois expérimentations sur l'acquisition, par des novices, de connaissances expertes. Les auteurs se basent sur la théorie des schémas, où chaque schéma est intégré dans un réseau sémantique composé de noeuds (les schémas) et de relations étiquetées et ordonnées. Ils étudient le « transfert » de ces schémas d'experts, représentés sous forme d'hypertexte (noeuds + liens typés) vers un novice, lors de la navigation. Les sujets doivent faire un rappel et répondre à des questions portant sur des jugements de proximités des relations, des relations sémantiques et des analogies. Les auteurs manipulent le facteur « information sur les relations disponible à l'écran » (information de type graphique, de type texte, pas d'information). Leurs résultats sur « répondre à questions » ne montrent pas de différence significative entre les trois groupes de sujets, tandis que le rappel est meilleur dans la condition « pas d'information sur les relations ». Enfin, en faisant varier la consigne (un groupe doit juste « apprendre », l'autre doit apprendre dans le but de créer plus tard un réseau sémantique de type hypertexte), ils obtiennent de meilleurs résultats (différence significative) aux « jugements de proximités » pour le 2e groupe. Les études longitudinales Les études longitudinales notent une satisfaction générale des utilisateurs, mais surtout un grande hétérogénéité des façons d'utiliser le même outil dans une population d'étudiants. Hutchings et ses collaborateurs [36] ont identifié des styles d'utilisateurs comme le « browser » qui navigue librement dans le système en suivant les liens de l'hypertexte et le « planificateur » qui fait une utilisation extensive de l'index et des contenus. A propos de l'influence des types de tâches sur le comportement des utilisateurs, ces mêmes auteurs disent que dans une tâche de prise de note, les sujets utilisent considérablement plus les liens de l'hypertexte que quand ils doivent répondre à un QCM. Ceux qui devaient « juste regarder » tentaient d'utiliser plus systématiquement les outils de navigation. Cependant, ceux qui devaient prendre des notes consultaient moins de noeuds qui ceux qui devaient répondre à un QCM. Le contraste est similaire entre ceux qui devaient prendre des notes et ceux qui devaient « juste regarder ». Ceux qui devaient « juste regarder » consultaient plus de noeuds graphiques/vidéo, et généralement une plus grande diversité d'informations, que ceux qui devaient prendre de notes. Smeaton (note 17) lui, distingue de cinq options de navigation : A. chercher (un point d'entrée) puis naviguer ; B. chercher un ensemble de noeuds et les consulter ; C. utiliser l'historique ; D. naviguer à partir de la préface ; E. utiliser l'index alphabétique. Ses 50 sujets utilisent le logiciel régulièrement comme complément de cours (1), périodiquement comme complément de cours (14), à la fin d'un ensemble de cours pour réviser un thème (17), ou comme révision juste avant les examens (39). Les sessions durent soit moins d'une heure (15) soit plus de 4 (17). Le reste (18) étant bien distribué entre les deux. Le nombre de sessions par étudiant se distribue régulièrement entre 1 et 10 fois, avec 5 sujets à + de 10 fois. Les sujets disent que la désorientation se manifeste autour de 30-45 minutes d'utilisation. Lors des premières utilisations, les sujets ont utilisé les options D (15), A (19) et E suivie de naviguer (16). Les travaux consacrés aux tâches d'acquisition de connaissances à l'aide d'un hypertexte présentent quelques résultats convergent avec ceux sur la recherche d'information [37] (par exemple dans le cadre de l'interrogation d'une base de données). Ils soulignent en particulier l'intérêt des hypertextes pour les tâches difficiles, exploratives, globales, à long terme, et à but flou [38]. Les tâches trop précises, trop locales semblent défavorisées par ces mêmes environnements. Un effort de description des tâches d'apprentissage doit selon nous être fait, qui distinguerait ce qu'il y a à apprendre (connaissances déclaratives / conceptuelles, procédures, schémas...) et l'implémentation dans le système des connaissances à apprendre. Sur le premier point, les résultats classiques de la psychologie cognitive, même s'ils ont été récemment nuancés [39], nous font penser que les hypertextes sont plutôt adaptés aux tâches d'acquisition de connaissances déclaratives. Pour d'autres types d'acquisitions, les hypertextes peuvent participer, à titre de support, mais l'important est bien entendu l'action, les exercices. Sur le deuxième point (l'instanciation des connaissances à apprendre dans le système), deux axes pourraient être choisis : (a) distinguer l'acquisition de connaissances de niveau local ce celles de niveau global ; (b) distinguer dans l'apprentissage le stockage, l'appariement et la production de connaissances. Ce n'est qu'à cette condition que l'on pourra définir rigoureusement des tâches pour les expérimentations et des variables dépendantes. Autres logiciels, autres résultats Il me semble important de souligner que les résultats rapportés ici ne concernent qu'un ensemble réduit de logiciels hypermédia pour l'apprentissage. La discussion qui suit évoque des situations qui a priori devraient être favorisées par ce type de logiciels. Pour certaines de ces situations, il est probable que la psychologie cognitive soit incapable d'obtenir des résultats, faute de pouvoir conduire des expérimentations. Il convient de se référer aux colloques « Hypermédias et apprentissages » et au dossier du département « Innovation pédagogiques » de la DLC consacré aux hypermédias (1993). Des outils très différents sont présentés, impliqués dans l'enseignement de quasiment toutes les disciplines. Les tutoriels CORREL (J.-P. Coste, Marseille) pour la physique et ARCADE (IMAG, Grenoble) pour l'algorithmique sont de véritables ateliers de travail pour les étudiants, pouvant servir de support à des activités allant des révisions et des exercices à l'exploration d'un thème, mais aussi de support de cours d'amphi et de TD. De nombreux autres outils rendent compte d'une originalité de démarche et d'une réflexion très intéressante sur ce que ce type d'outil pourrait apporter à une situation d'enseignement considérée. Le seul « problème » est que les quelques évaluations de ces outils sont centrées... sur les outils et non sur les activités mentales des sujets qui les utilisent. Du coup, ces évaluations sont difficilement exploitables par des développeurs de logiciels. Il semble toutefois important de souligner que les développements récents en France, mais aussi en Europe et aux États-Unis, intègrent les disciplines littéraires avec succès (analyse d'énoncés, composition de texte, comparaison de documents...) et surtout les activités de création, de développement de petites applications. DISCUSSION : à quels types d'apprentissages les logiciels hypermédia peuvent-ils être utiles ? Quelques résultats expérimentaux, issus de démarches analytiques centrées sur l'activité du sujet, et non sur le modèle de tâche, montrent l'intérêt des hypertextes pour les tâches difficiles, exploratives, globales, à long terme, et à but flou. Cependant la psychologie cognitive et la recherche sur les hypertextes doivent faire des progrès dans la définition des tâches d'apprentissage, afin que l'on puisse vraiment exploiter et comparer ces résultats, et avoir une réponse plus claire à la question ici posée. Des apprentissages moins traditionnels semblent favorisés par ce type d'environnement : l'apprentissage par la découverte [40], la mise en relation de concepts, le développement d'applications et les travaux collaboratifs. Le problème actuel semble être de modéliser l'activité des sujets dans ce type d'environnement. - En premier lieu, il me semble qu'il faille revenir sur une illusion : ce n'est pas parce qu'un sujet est libre de choisir qu'il fait des choix pertinents par rapport à la situation qu'il a à traiter. Tout simplement parce que sa représentation de la situation à traiter peut ne pas être claire et/ou ne pas correspondre à l'organisation des données dans le logiciel. - Deuxièmement, il faudrait modéliser l'articulation de deux activités mentales : la localisation des items dans le système et le traitement des contenus. Les échecs et les difficultés d'utilisation viennent souvent de problèmes à l'un de ces deux niveaux, sans que l'on sache vraiment préciser lequel. Ensuite, on ne sait actuellement pas comment étudier l'activité de localisation dans un système hypermédia, et plus largement dans les systèmes de gestion de données. Simplement parce que la localisation passe à la fois par une prise de repères (informations disponibles au niveau de l'interface), par la compréhension des relations au niveau local (relation entre deux items) et au niveau global (logique d'organisation du système). - Troisièmement, il serait peut-être temps de se pencher sur l'apprentissage comme une activité de recherche-intégration de connaissances, soit, pour être clair, assimiler la recherche d'information (« information retrieval » n'a pas de bonne traduction en Français) et certains types d'apprentissages. Cette proposition a selon moi deux avantages : elle propose de comparer des traitements cognitifs dans des environnements identiques ; elle nous oblige à considérer qu'une recherche d'information ne peut se faire que s'il y a une question de la part du sujet, un problème pour lui. Or : un problème n'est pas quelque chose d'absolu, il est interprété, représenté par le sujet (i.e. l'activité de problématisation) ; sans problème il n'y pas de recherche d'information et donc... pas d'intégration. - Quatrièmement [41], s'il l'on admet a minima que certains apprentissages consistent à rechercher-intégrer un ensemble large et complexe d'informations (par exemple vous voulez apprendre un nouveau langage informatique) et que l'on admet aussi qu'un même corpus peut être appris par des personnes différentes ayant des problèmes différents à régler, alors élaborer un modèle de l'apprenant devient illusoire. D'autre part, des résultats récents montrent que les experts d'un domaine ne raisonnent pas logiquement (dans le sens « classique ») mais fonctionnellement dans un contexte : chez un expert, une même connaissance peut être disponible dans deux contextes fonctionnels différents. Alors on peut considérer que le problème de l'enseignement de certains corpus n'est pas tellement de « s'adapter » aux élèves mais de leur donner la possibilité d'accéder quand ils le décident aux informations pertinentes hic et nunc. Autrement dit d'organiser et d'indexer rationnellement le corpus (Fig. 1).
Figure 1 : la proposition de Bastien : CONCLUSION Après une phase d'enthousiasme envers les hypermédias, qui requièrent un apprenant actif, sans lui imposer, a priori, de contrainte (fin des années 80), on a admis au début des années 90 que ce principe d'interaction ne rendait pas pour autant les systèmes opérationnels. Mais on a retenu que le principal intérêt des hypertextes pour l'apprentissage était peut-être de permettre aux enseignants d'innover en EAO, de tester des idées difficiles à réaliser dans d'autres environnements. L'utilisation d'hypermédias pour l'apprentissage a donné lieu à des évaluations et à des expérimentations. Les évaluations ont (quasiment) par principe une portée limitée au système évalué lui-même. Les résultats expérimentaux obtenus commencent à nous éclairer sur les activités qui sont véritablement favorisées les environnements hypermédia (tâches difficiles, exploratives, globales, à long terme, et à but flou). Ces résultats sont néanmoins difficiles à exploiter parce que peu comparables entre eux ; cette restriction a été analysée comme conséquente à une absence de modélisation des tâches d'apprentissage. D'autre part ces résultats ne concernent qu'une partie réduite de l'utilisation réelle des hypermédias pour l'apprentissage. Ils soulèvent aussi des problèmes qui méritent d'être pris en compte par les enseignants et les concepteurs sur la pertinence de l'agencement des connaissances à transmettre et sur la nature des connaissances acquises. Enfin, il apparaît que les hypertextes sont le meilleur moyen d'étudier l'apprentissage par le texte. André Tricot Remerciements : ma recherche est soutenue par une allocation de recherche du Ministère de la Recherche et de l'Espace au sein du CREPCO. Les incessantes discussions que j'ai avec mon camarade Jean-François Rouet sur le thème abordé ici ont probablement influencé positivement ce papier. Paru dans la Revue de l'EPI n° 76 de décembre 1994. NOTES [1] - B. de La Passardière & G.-L. Baron (Eds.). Hypermédias et Apprentissages, Actes des 1er journées scientifiques, Châtenay-Malabry, Paris : Presses de INRP ; 1992 ; [2] - Pour une revue de questions plus complète sur l'utilisation des hypermédias, voir Tricot, A. La navigation dans les hypertextes et les hypermédias. Bibliographie commentée, CREPCO Technical Repport n° 9401, Université de Provence, Aix en Provence (112 p.). [3] - La juxtaposition de deux significations différentes du mot contexte dans le même paragraphe est délibérée. Elle fait référence au débat entre Herbert Simon et John Anderson (In K. van Lehn (Ed.), Architectures for intelligence, Hillsdale, NJ: Lawrence Erlbaum Associates, 1991) : le contexte d'une tâche est-il celui de l'expérimentateur ou celui du sujet ? « ce que traite le sujet » (des données dans un contexte en fonction d'une finalité) est-il un observable correct ? Ce débat me semble particulièrement sensible dans le contexte de l'apprentissage. [4] - Anderson, J.R. Skill acquisition : compilation of weak method problem solutions, Psychological Review, 94 (2), 192-210, 1987. [5] - Anderson, J.R., Boyle, C.F., Corbett, A.T. & Lewis, M.W. Cognitive modeling and intelligent tutoring, Artificial Intelligence, 42, 7-49, 1990. [6] - Inhelder, B. & Cellérier, G. (Eds.). Le cheminement des découvertes de l'enfant, Neuchâtel: Delachaux et Niestlé, 1992. [7] - Anderson, J.R. A theory of the origins of human knowledge, Artificial Intelligence, 40, 313-351, 1989. [8] - Voir Anzaï, Y. & Simon, H.A. The theory of learning by doing, Psychological Review, 86 (2), 124-140, 1979, [9] - Ripoll, T. Recherche en mémoire d'un problème analogue, Thèse de l'Université de Provence, Aix en Provence, 1993. [10] - Pierce, K.A., Duncan, M.K., Gholsn, B., Ray, G.E. & Kambi, A.G. Cognitive load, schema acquisition, and procedural adaptation in nonisomorphic analogical transfer. Journal of Educational Psychology, 85 (1), 66-74, 1993. [11] - Un schéma est un type de connaissance complexe acquise par le sujet, qui lui permettra de traiter une situation nouvelle à partir de sa connaissance « schématique » de ce type de situation. [12] - Denhière, G., & Mandl, H. (Eds.). Knowledge acquisition from text and picture, European Journal of Psychology of Education, Special issue, vol. III (2), 1988, [13] - Mannes, S. A theoretical interpretation of learning vs. memorizing text, in G. Denhière & H. Mandl (Eds.), Knowledge acquisition from text and picture, European Journal of Psychology of Education, Special issue, vol. III (2), 157-162, 1988. [14] - Wright, P., Hypertext as an interface for learners : some human factors issues, In D.H. Jonassen & H. Mandl (Eds.), Designing hypermedia for learning, Proceedings of the NATO Advanced Research Worshop, Rottenburg/Neckar. Heidelberg: Springer Verlag, 1990. [15] - Reader, W. & Hammond, N. Computer-based tools to support learning from hypertext : concept mapping tools and beyond, Computers Education, 22 (1/2), 99-106, 1994. [16] - Hutchings, G.A., Hall, W. & Thorogood, P. Experiences with hypermedia in undergraduate education, Computers Education, 22 (1/2), 39-44, 1994. [17] - Smeaton, A.F. Using hypertext for computer based learning, Computers Education, 17 (3), 173-179, 1991. [18] - Conklin, J. Hypertext: an introduction and survey, IEEE Computer, 20 (9), 17-41, 1987. [19] - Nelson, T.H. A file structure for the complex, the changing and the indeterminate, Proceedings of the 20th ACM National Conference, New York : ACM Press, 1965. [20] - Bush, V. As we may think, In J.M. Nyce & P. Kahn (1991) (Eds.), From Memex to Hypertext : Vannevar Bush and the mind's machine. Boston : Academic Press (dernière édition de cet article qui date de 1945). [21] - Andonoff, E., Mendiboure, C., Morin, C., Rougier, V. & Zurfluh, G. OHQL : un langage graphique pour l'interrogation d'une base de données, Ingénierie des Systèmes d'Information, 1 (2), 203-227, 1993. [22] - Thompson, R.H., & Croft, W.B. Support for browsing in an intelligent text retrieval system, International Journal of Man-Machine Studies, 30, 639-668, 1989, et Girill, T.R. & Luk, C.H.Hierarchical search support for hypertext on-line documentation, International Journal of Man-Machine Studies, 36, 571-585, 1992. [23] - La grand précurseur dans le domaine est Douglas Engelbart, dont les articles les plus importants ont été réédités dans I. Greif (Ed.), Computer Supported Cooperative Work : a book of readings. San Mateo, CA : Morgan Kaufman, 1988. Pour des développements récents, voir Rein, G.L., & Ellis, C.A. rIBIS : a real time group hypertext system, International Journal of Man-Machine Studies, 34, 349-367, 1991, et, Marshall, C.C., Halasz, F.G., Roger, R.A., & Jansen, W.C. Aquanet : a hypertext tool to hold your knowledge in place, Hypertext'91 Proceedings, San Antonio, New-York, NY : ACM Press, 1991. [24] - Bernstein, M. Storyspace : Hypertext and the process of writing, in E. Berk & J. Devlin (Eds.), Hypertext / Hypermedia handbook. New-York, NY : Mc Graw Hill, 1991 ; [25] - Bernstein, M. Enactment in information farming, Hypertext'93 Proceedings, Seattle, New-York, NY : ACM Press, 1993. [26] - Tricot, A. Un point sur l'ergonomie des interfaces hypermédia, Le Travail Humain, sous presse. [27] - Stanton, N.A., & Stammers, R.B. Learning styles in a non-linear training environment, In R. Mc Aleese & C. Green (Eds.), Hypertext : State of the Art. Oxford : Intellect Ltd, 1990. [28] - Glaser, R. The reemergence of learning theory within instructional research, American Psychologist, 45, 29-39, 1990. [29] - Dillenbourg, P., Hilario, M., Mendelsohn, P., Schneider, D., & Borcic, B. Intelligent learning environments, NFP Project Repport, TECFA, Faculté de Psychologie et des Sciences de l'Éducation, Genève, 1993. [30] - Bastien, M. Cognitive ergonomics in a language learning task, In A. Oliveira (Ed.), Hypermedia courseware : structures of communication and intelligent help, Proceedings of the NATO Advanced Research Wokshop, Espinho, Portugal. Berlin : Springer Verlag, 1992. [31] - Silva, A.P. Hypermedia : influence of interactive freedom degree in learning processes, In A. Oliveira (Ed.), Hypermedia courseware : structures of communication and intelligent help, Proceedings of the NATO Advanced Research Wokshop, Espinho, Portugal. Berlin : Springer Verlag, 1992. [32] - Rouet, J.-F. Cognitive processing of hyperdocuments : when does nonlinearity help?, In D. Lucarella, J. Nanard, M. Nanard & P. Paolini (Eds.). ECHT'92, Proceedings of the 4th ACM Conference on Hypertext, Milano. New-York : ACM Press, 1992. [33] - Gordon, S., Gustavel, J., Moore, J., & Hankey, J. The effect of hypertext on reader knowledge representation, Proceedings of the 32nd Annual Meetings of the Human Factors Society, Santa Monica, CA : Human Factors Society, 1988. [34] - Dee-Lucas, D., & Larkin, J.H. Text representation with traditional text and hypertext, Carnegie Mellon University, Department of Psychology, Technical Repport H.P. #21, 1992. [35] - Jonassen, D.H. & Wang, S. Acquiring structural knowledge from sementically structured hypertext, Journal of Computer-Based Interaction, 20 (1), 1-8, 1993. [36] - Hutchings, G.A., Hall, W., & Thorogood, P., Experiences with hypermedia in undergraduate education, Computers Education, 22 (1/2), 39-44, 1994. [37] - Rouet, J.-F., & Tricot, A. Task and activity model in the design of hypertext. In H. van Oostendorp (Ed.), Cognitive aspects of electronic text processing, Norwood, NJ : Ablex Publishing (in prep). [38] - Ici, « but flou » réfère à la représentation que le sujet se fait de l'implémentation du but à atteindre dans le système. En revanche, la finalité générale (par exemple « apprendre ») doit être clairement identifiée. [39] - par exemple Byrnes, J.P., The conceptual basis of procedural learning, Cognitive Development, 7, 235-257, 1992. [40] - Jacobs, G. Hypermedia and discovery-based learning : a historical perspective, British Journal of Educational Technology, 23 (2), 112-121, 1992. [41] - Cette dernière proposition rapporte les grandes lignes de certains travaux de l'équipe de Claude Bastien, dont je fais partie (CNRS - Université d'Aix en Provence). ___________________ |